ML Engineering
Production-grade model infrastructure, training, evaluation, serving and monitoring that holds up at scale, with cost kept firmly under control.
ML engineering is the discipline of taking machine-learning models from notebook to production: building the pipelines that train and evaluate them, the infrastructure that serves them with low latency, and the monitoring that keeps them honest. It's the difference between a model that demos well and one you can trust in production.
What's included
- Evaluation & guardrails, Golden datasets, automated evals and safety rails so quality is measured, not guessed.
- Vector & feature stores, The retrieval and feature infrastructure that powers RAG and predictive models.
- Low-latency serving, Optimized model serving that meets your latency and throughput targets.
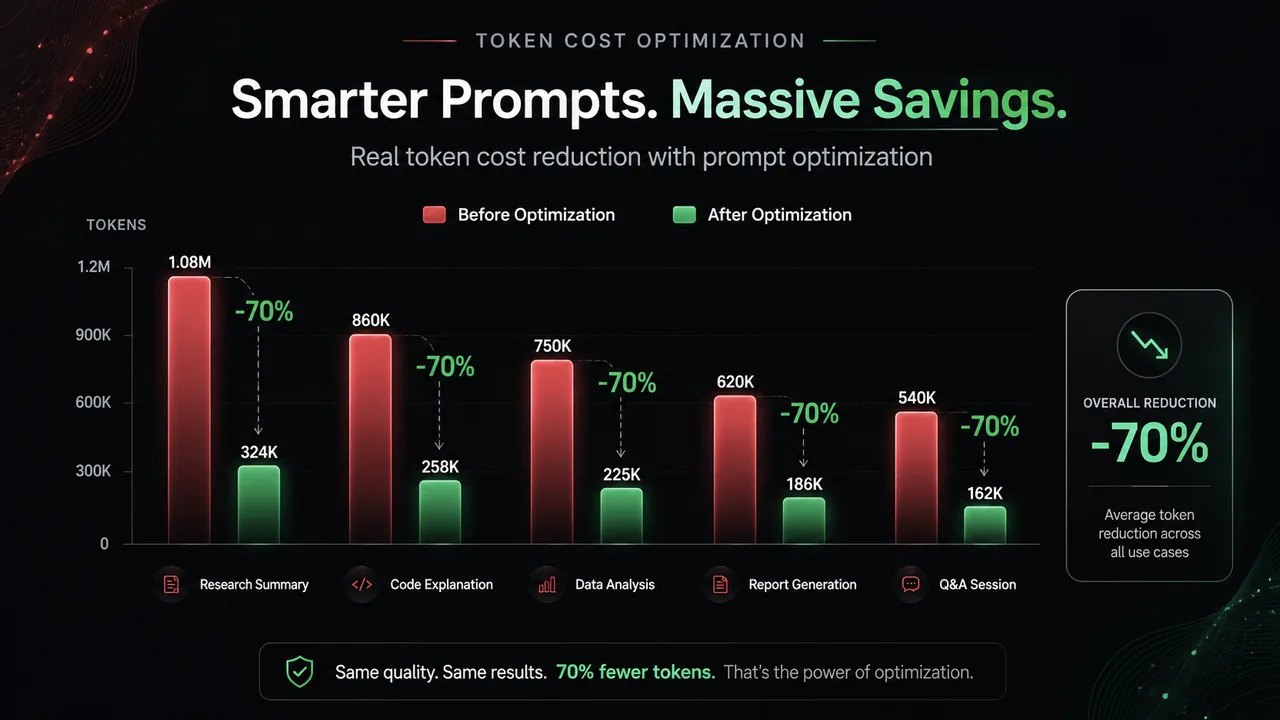
- Cost optimization, Caching, routing and distillation to keep inference bills sustainable.
Our approach
We build the evaluation harness first, without a way to measure quality, every change is a guess. Then we stand up serving, retrieval and feature infrastructure, and wrap it in monitoring that catches drift before users do.
The outcome is ML you can ship and sleep on: measured, observable, and cost-aware.
From idea to shipped in four phases.
Evaluate
Build the golden set and eval harness.
Serve
Stand up low-latency model serving.
Retrieve
Add vector and feature stores.
Monitor
Track quality, drift and cost in production.
Frequently asked questions
Why build an evaluation harness first?
Without a way to measure quality, every model change is a guess and regressions slip into production. We assemble a golden set of inputs and expected outputs early, so every change is scored objectively and improvements are real.
How do you reduce inference cost?
We use a combination of caching, smart model routing, prompt optimization and distillation to smaller models, often cutting inference bills by half or more without a meaningful drop in quality.
What does production ML monitoring track?
We monitor output quality against evals, input and output drift, latency, throughput and cost. That lets us catch problems the same day rather than in a support ticket weeks later.