Cutting our token bill by 70% without losing quality
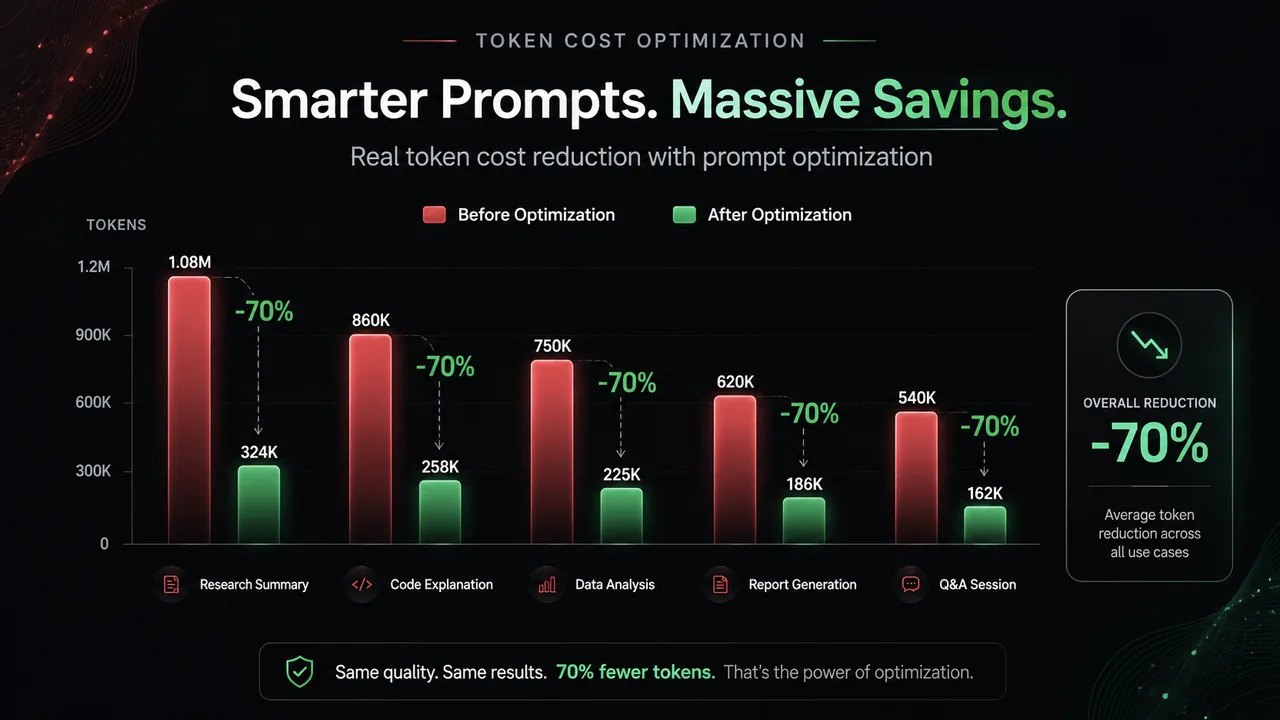
Inference cost is a feature you can ship. Here are the levers that actually moved our token bill, by about 70%, without users noticing a drop.
Measure before you cut
You can't optimize a cost you can't see. The first step is per-request, per-feature cost tracking tied to your eval suite, so every optimization is checked against quality. Cutting cost while quietly degrading answers is not a win.
Cache aggressively
A surprising share of requests are near-duplicates. Caching exact and semantically similar responses, with sensible invalidation, removes whole categories of spend before the model is even called.
- Exact-match caching for repeated prompts.
- Semantic caching for near-duplicate questions.
- Cache embeddings and retrieval results, not just final answers.
Route by difficulty
Not every request needs your most expensive model. We classify requests and route easy ones to smaller, cheaper models, reserving the frontier model for the hard cases. Most traffic is easy, so the savings are large.
Send the easy 80% to a small model and the hard 20% to the big one, quality holds, cost drops.
Distill and trim prompts
For high-volume tasks, we distill behavior into a smaller fine-tuned model. And we audit prompts: long system prompts and redundant context are paid for on every call. Trimming them is free quality-neutral savings.
Key takeaways
- Track cost per request against your evals.
- Cache exact and semantically similar responses.
- Route easy requests to cheaper models.
- Distill high-volume tasks and trim fat prompts.
Working on something like this? Tell us about it, it's exactly the kind of problem we love.
Frequently asked questions
How can I reduce LLM API costs?
The biggest levers are caching repeated and semantically similar responses, routing easy requests to smaller cheaper models while reserving frontier models for hard cases, distilling high-volume tasks into fine-tuned small models, and trimming redundant prompt context. Together these often cut costs by half or more.
Does cutting token cost hurt output quality?
Not if you measure. By tying every optimization to an evaluation suite, you keep quality flat while removing spend. Caching and routing in particular reduce cost with no quality impact on the affected requests.
What is model routing?
Model routing classifies each request by difficulty and sends it to the cheapest model that can handle it. Since most production traffic is easy, routing the bulk to a small model and only the hard cases to a large one yields large savings.