Designing agents that don't go rogue
Everyone wants autonomous agents until one emails a customer the wrong thing. Autonomy is a dial, not a switch, here's how we set it safely.
Autonomy is a dial
The most common agent mistake is treating autonomy as on or off. In practice every step in a workflow has its own risk profile. Reading a document is safe; sending an irreversible message is not. We set the autonomy level per step, not per agent.
Guardrails before capability
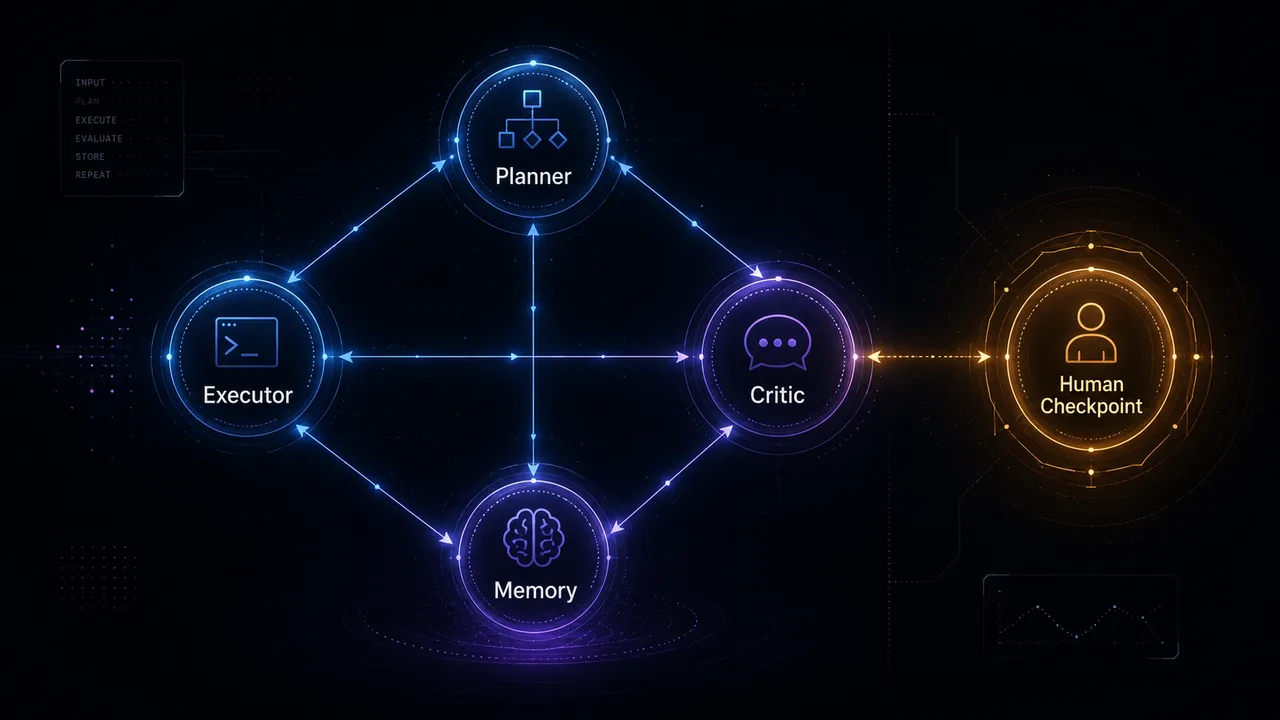
Before we give an agent a powerful tool, we constrain how it can use it. Tools are scoped, inputs are validated, and dangerous actions require explicit confirmation. The agent operates inside a fence it cannot climb, not an open field.
- Scope every tool to the minimum it needs.
- Validate and sanitize tool inputs and outputs.
- Gate irreversible actions behind a human checkpoint.
Evaluate the agent like a system
Agents are non-deterministic, so we evaluate them on suites of realistic scenarios and track success and failure rates over time. When we change a prompt or a tool, the eval tells us whether the whole system got better or just different.
An agent you can't evaluate is an agent you can't trust at scale.
Keep a human in the loop where it counts
The goal isn't to remove people, it's to remove busywork while keeping judgment where it matters. A well-designed human checkpoint adds seconds, prevents disasters, and builds the trust that lets you widen autonomy over time.
Key takeaways
- Set autonomy per step, by risk, not per agent.
- Scope tools and gate irreversible actions.
- Evaluate agents on realistic scenario suites.
- Keep humans where judgment matters most.
Working on something like this? Tell us about it, it's exactly the kind of problem we love.
Frequently asked questions
What is an AI agent?
An AI agent is a system where a language model plans and takes actions by calling tools, searching, writing to a database, sending a message, to complete a multi-step task. Unlike a single prompt, an agent loops: it acts, observes the result, and decides what to do next.
How do you stop AI agents from making mistakes?
By treating autonomy as a per-step dial, scoping every tool to the minimum needed, validating inputs and outputs, gating irreversible actions behind human approval, and evaluating the agent on realistic scenarios so regressions are caught before release.
Should agents run fully autonomously?
Rarely. The safe pattern is to let low-risk steps run unattended while routing anything irreversible through a human checkpoint. As evaluation builds confidence, you can widen autonomy deliberately.